Adding copyright information for images on Hugo based website

As you are aware, when you create your post with images and publish them on your website, sooner or later they will appear on Google.
Your article will land in Search Results and images will be shown in Google Images.
Sometimes you are taking a lot of effort into your images and restricting their use by providing specific disclaimers or copyright information on your website.
The problem is that Google does not always know that and when you search for an image, that is sourced from your website, the image may be copyright restricted.
The user, who is searching through, will not know that as well and he may come into trouble. This may result in a fine that may need to be paid to the rightful owner.
Of course, Google protects itself by always adding information under the picture in search results:
Images may be subject to copyright.
This text contains also a link to learn more about copyright.
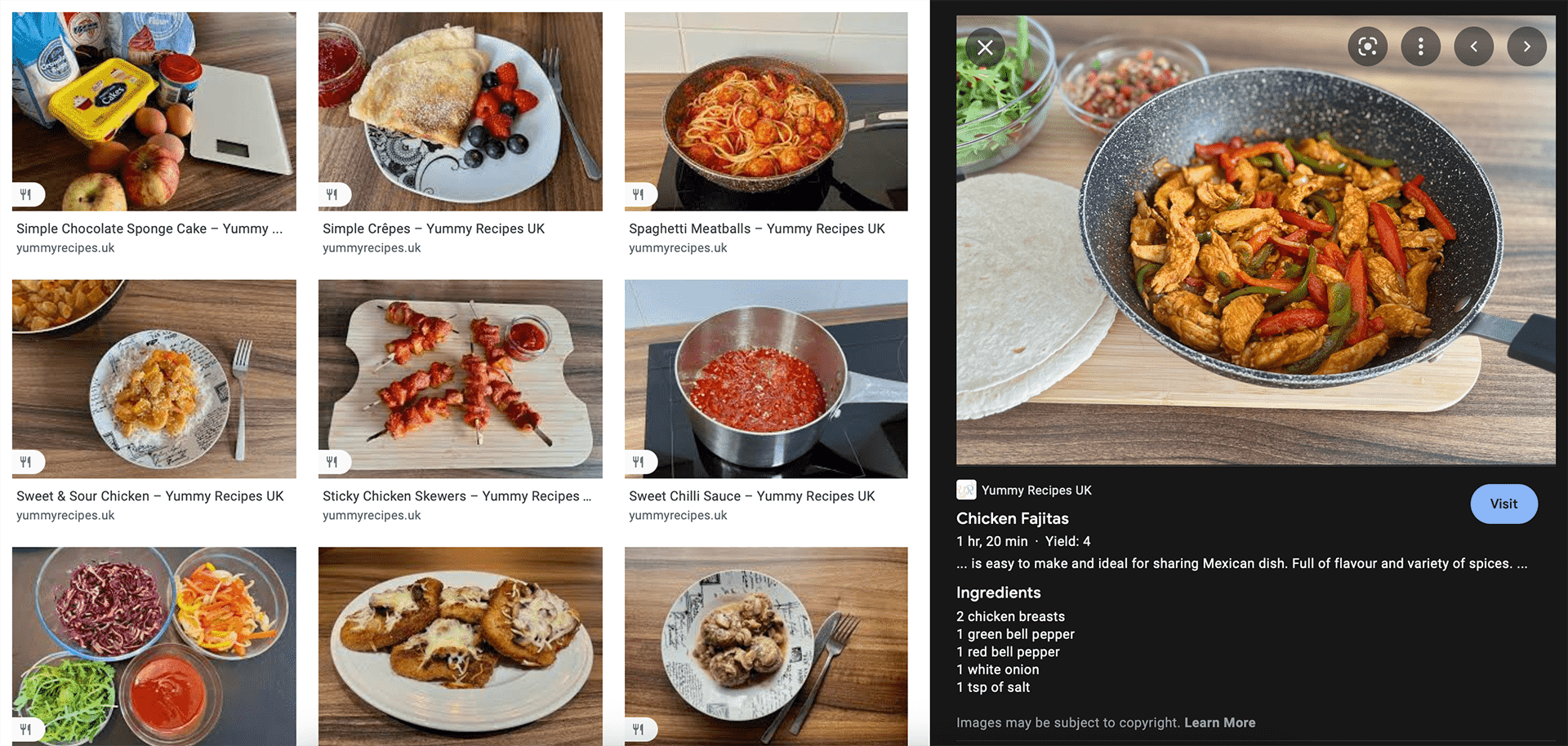
This not always may be enough, or for us, rightful owners, we would like to inform more about the restricted use of our work.
Luckily, you may add data to Google Image Search results that contain information about copyrights. This is added through structured data (schema) and is very useful, yet not complicated.
Structured data for images can add a link, that will appear under the photo and may contain a reference to the creator, how the image can be used and what are use restrictions (licenses, permissions etc.).
Google describes it in Search Central documentation (Image metadata in Google Images).
If our images are copyright restricted, by providing information for a licence (terms of use), we may be eligible for:
“the Licensable badge, which provides a link to the license and more detail on how someone can use the image”
One of my websites, that restricts the use of the images, is YummyRecipes.uk and I have looked into including relevant structured data (not typically visible for ordinary visitors) to make users aware, that they cannot just copy the image and use them as theirs. If they do, they need to be aware of potential legal consequences.
I know, that many users will still don’t bother and will “steal” somebody’s property and use it as theirs, but better this than nothing, especially if at some point you will decide to pursue your rights.
Hugo, the static site generator, is such a handful tool, that you can implement plenty of things (way above typical SSG ideology), that can be run on your behalf during the site build. Once all set, this result limits the need for you to do anything extra and just concentrate on the content.
When composing a post in Hugo we use markdown files. All the images are added in markdown form. The idea will be to grab all links to the images from the content of the document and reuse them in structured data form.
Additionally, some images (like featured images), are added by users in frontmatter, hence we will need to get that as well.
At this stage, we will not need to bother with performance and image optimisation that you normally do (serving in various sizes), but just to grab and provide a link to full-size images and add additional data (licence information) along.
Of course, this part - performance of our images, needs to be already implemented, following Google Images best practices, before our images will appear in image search results. I assume that this is already done by you and your images are displaying there correctly.
There are two ways of adding licence information to your photos. You can add structured data or embed information directly into the photo itself.
I am not a fan of embedding data as this can be easily removed or lost during image processing and optimisation. This is why I am concentrating on Structured data (schema), specifically in JSON-LD format.
My main goal is to add a link to copyright information and a creator of the image (copyright holder).
Grab the URL for all images
Firstly, let’s grab all images per post in Hugo. For this, we can use this handy code for use in our layout.
Credit to Joe Mooring from Hugo Community for pointing into right direction.
{{ range findRE `(?s)<img.+?>` .Content }}
{{ replaceRE `(?s).*src="(.+?)".*` "$1" . }}
{{ end }}
That will return images URL from the content that we will need to build our structured data.
Site config parameters
Before we do that, it’s worth setting a couple of things first.
You need to have a page where you will describe Copyright Information, and if you need, specify an additional page, where somebody can contact you requesting rights for use.
I decided, that I need only one page and link to it I provided in my config.toml file.
[params]
copyright_url = "/copyright/"
I already have specified an author (copyright holder) and I will use the site title at some point.
title = "Site Name"
[params.author]
name = "Name Surname"
Schema with image metadata
The initial schema will look as below.
<script type="application/ld+json">
[{{ range $k, $_ := findRE `(?s)<img.+?>` .Content }}{{ if $k }},{{ end }}
{
"@context": "https://schema.org/",
"@type": "ImageObject",
"contentUrl": {{ replaceRE `(?s).*src="(.+?)".*` "$1" . | absURL }},
"license": {{ $.Site.Params.copyright_url | absURL }},
"acquireLicensePage": {{ $.Site.Params.copyright_url | absURL }},
"creditText": {{ $.Site.Title }},
"creator": {
"@type": "Person",
"name": {{ $.Site.Params.Author.name }}
},
"copyrightNotice": {{ $.Site.Params.Author.name }}
}{{ end }}
]
</script>
On the page where I will be implementing it, most posts (recipes) will contain images, but to avoid serving an empty script tag when there are no images, we will add a condition for that.
{{ if (findRE `(?s)<img.+?>` .Content) }}
// our above code
{{end}}
Adding images from frontmatter
If we have images added in frontmatter, like typically featured images, we can add that as well in the following way:
{{ if .Params.featuredImage }}
{{- $ftimgsrc := "" -}}
{{ if hasPrefix .Params.featuredImage "/" }}
{{ $ftimgsrc = resources.Get .Params.featuredImage }}
{{ else }}
{{ if .Page.BundleType }}
{{ $ftimgsrc = .Page.Resources.GetMatch .Params.featuredImage }}
{{ else }}
{{ $path := path.Join .Page.File.Dir .Params.featuredImage }}
{{ $ftimgsrc = resources.Get $path }}
{{ end }}
{{ end }}
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "ImageObject",
"contentUrl": {{ $ftimgsrc.Permalink }},
"license": {{ $.Site.Params.copyright_url | absURL }},
"acquireLicensePage": {{ $.Site.Params.copyright_url | absURL }},
"creditText": {{ $.Site.Title }},
"creator": {
"@type": "Person",
"name": {{ $.Site.Params.Author.name }}
},
"copyrightNotice": {{ $.Site.Params.Author.name }}
}
</script>
{{ end }}
The full code
In such a way, we will have two parts that will work for us. One will be served if there is a featured image set (via featuredImage in frontmatter) and the second when there are images found in the content.
The code will look as follow:
{{ if .Params.featuredImage }}
{{- $ftimgsrc := "" -}}
{{ if hasPrefix .Params.featuredImage "/" }}
{{ $ftimgsrc = resources.Get .Params.featuredImage }}
{{ else }}
{{ if .Page.BundleType }}
{{ $ftimgsrc = .Page.Resources.GetMatch .Params.featuredImage }}
{{ else }}
{{ $path := path.Join .Page.File.Dir .Params.featuredImage }}
{{ $ftimgsrc = resources.Get $path }}
{{ end }}
{{ end }}
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "ImageObject",
"contentUrl": {{ $ftimgsrc.Permalink }},
"license": {{ $.Site.Params.copyright_url | absURL }},
"acquireLicensePage": {{ $.Site.Params.copyright_url | absURL }},
"creditText": {{ $.Site.Title }},
"creator": {
"@type": "Person",
"name": {{ $.Site.Params.Author.name }}
},
"copyrightNotice": {{ $.Site.Params.Author.name }}
}
</script>
{{ end }}
{{ if (findRE `(?s)<img.+?>` .Content) }}
<script type="application/ld+json">
[{{ range $k, $_ := findRE `(?s)<img.+?>` .Content }}{{ if $k }},{{ end }}
{
"@context": "https://schema.org/",
"@type": "ImageObject",
"contentUrl": {{ replaceRE `(?s).*src="(.+?)".*` "$1" . | absURL }},
"license": {{ $.Site.Params.copyright_url | absURL }},
"acquireLicensePage": {{ $.Site.Params.copyright_url | absURL }},
"creditText": {{ $.Site.Title }},
"creator": {
"@type": "Person",
"name": {{ $.Site.Params.Author.name }}
},
"copyrightNotice": {{ $.Site.Params.Author.name }}
}{{ end }}
]
</script>
{{ end }}
Validation
The last step will be a validation using the Rich Results Test tool.
If all goes well, we shall see a new position called Image metadata.

Of course, the change in Google Image Search will not appear straight away as Google Robots need to crawl new information, but at least it’s there already.




